AgentStatus x Talkdesk, a quick map of how we fit
Independent verification for Autopilot and the agents behind your CX.
We continuously test Talkdesk-powered AI experiences from outside the stack and check whether the answers are correct across customer-facing chat flows, from 800+ nodes across 30 countries. For public Talkdesk web chat, AgentStatus does not need OAuth credentials, bearer tokens, private customer data, or a formal integration. We test the same public-facing path a user would hit.
What we understand about Talkdesk
A CX platform with deep inside-out visibility.
Talkdesk spans the full contact center lifecycle: Autopilot for AI self-service, Navigator for omnichannel routing, Copilot for agent assistance, Studio for workflow orchestration, and Quality Management for interaction evaluation.
The inside-out visibility is substantial: Talkdesk Explore delivers operational metrics and dashboards, Talkdesk Live tracks real-time SLAs and performance, Data Platform APIs support reporting and BI workflows, and the CXA Operations Center surfaces transcripts, sentiment, and quality oversight.
That makes Talkdesk strong at answering: what happened inside the CX platform?
AgentStatus answers a complementary question: what did the customer-facing AI experience actually return when tested from the outside?
What AgentStatus is
Outside-in checks on what the AI actually returned.
AgentStatus continuously tests AI agents from outside the stack and checks whether the responses match known-correct expectations.
We send controlled synthetic prompts to production or staging agents, capture the actual response, and evaluate uptime, latency, semantic correctness, drift, and guardrail behavior. When something changes, fails, or degrades, we attach the evidence: prompt, response, timing, region, verdict, and failure reason.
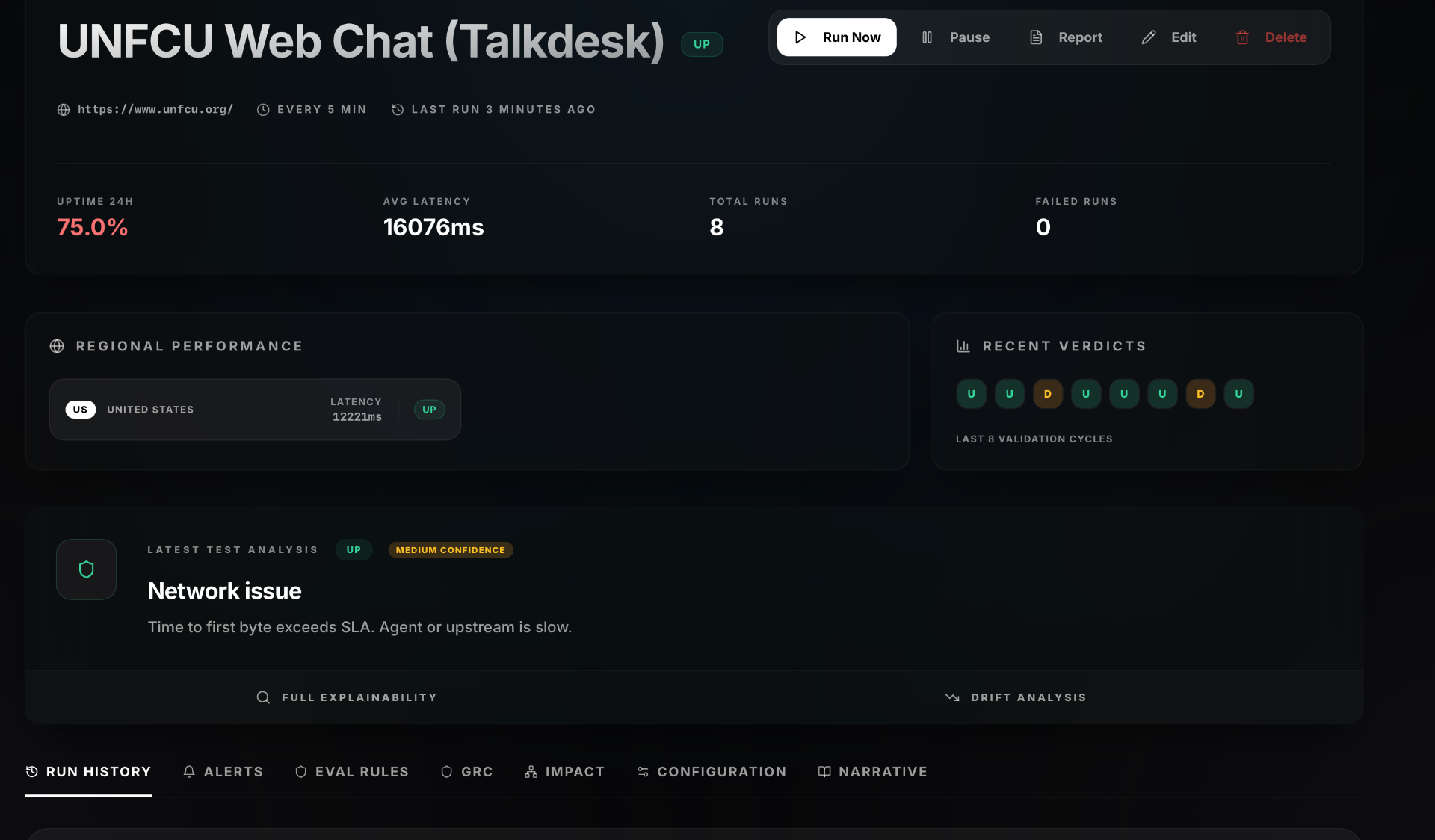
We already monitor a real Talkdesk-powered public web chat: UNFCU's member-support chat. That monitor sends safe support prompts like:
- • "What are your support hours?"
- • "How can I contact member service?"
- • "What can you help me with?"
This proves the path is not theoretical. We can validate real Talkdesk-powered customer experiences from the outside.
Where we fit
Complement, not overlap.
Outside-in vs inside-out
Talkdesk sees what happens inside the platform: routing, transcripts, dashboards, quality workflows, and operational metrics. AgentStatus sees what a customer-facing validate actually receives from a specific geography, network path, and latency profile.
Production truth, not only dashboards
A dashboard can look healthy while the AI experience gives an outdated answer, generic fallback text, or inconsistent responses across regions. AgentStatus catches those customer-facing failures.
Global execution footprint
Our validations run from 800+ nodes across 30 countries. That matters for global CX deployments where failures can be regional, network-specific, or dependent on the public widget path.
No integration required for public web chat
For public Talkdesk web-chat experiences, AgentStatus uses an HTTP-native adapter. It resolves the public Talkdesk touchpoint, bootstraps the live-chat flow, sends synthetic prompts, reads actual assistant replies, and scores the response. No Talkdesk OAuth. No bearer token. No browser farm. No private customer data.
The split
Two truths, one story.
Talkdesk, Inside-out
- • Autopilot self-service flows
- • Navigator routing and omnichannel
- • Copilot agent assistance
- • Explore dashboards and reporting
- • Live real-time operational metrics
- • Data Platform API exports
- • CXA Operations Center transcripts and quality workflows
AgentStatus, Outside-in
- • Continuous synthetic validate traffic
- • Expected-answer checks
- • Semantic drift detection
- • Public widget-path validation
- • 800+ nodes across 30 countries
- • Latency, uptime, and response evidence
- • Guardrail and policy verification
Proof of scale
Plain definitions, no inflation.
In about two months, AgentStatus has executed on the order of 18 million validate runs across the network.
We also maintain on the order of 6,000 agent records in our system, meaning rows and configurations we track across evaluation, monitoring, and pipeline agents, not "6,000 paying customers."
For Talkdesk specifically, we have already built and shipped an HTTP-native Talkdesk monitor for UNFCU's public member-support web chat. It validates real assistant replies, not just whether a widget loads.
If helpful, we can share stricter production-only definitions under NDA.
What we are not claiming
An independent layer that coexists.
We are not a replacement for Talkdesk Explore, Talkdesk Live, or the CXA Operations Center.
We are not claiming privileged access to Talkdesk private APIs, private customer conversations, or enterprise tenant data.
We are not saying every Talkdesk deployment can be monitored identically without approval. For public web-chat monitoring, the right posture is approved synthetic prompts, known expected answers, and clear boundaries around what is tested.
AgentStatus is an independent validation layer that coexists with Talkdesk and gives teams outside-in proof of what the AI experience returned.
What we'd like from this conversation
Asks.
A two-week outside-in pilot
One approved Talkdesk-powered customer-facing experience, public or staging. We define safe synthetic scenarios, expected answers, geography, cadence, and alert thresholds. No OAuth credentials or bearer tokens required for public web chat.
Approved test scenarios and expected answers
A small set of prompts that represent real customer intents, plus the answer criteria Talkdesk or the customer expects the AI to satisfy.
Where independent proof is most useful
We should decide whether the best starting point is Talkdesk-internal QA, a joint customer scenario, or a prospect-facing proof point where the buyer wants independent assurance alongside Talkdesk's own analytics.
Closing
Talkdesk helps enterprises resolve customer requests autonomously at scale. AgentStatus helps those enterprises prove, continuously, that the AI experience behaves the way policy and customers require, globally, with evidence that holds up under scrutiny. We can already validate Talkdesk-powered public web chat from the outside. The next step is choosing the right approved scenario and turning that into a repeatable proof point.
Metrics are stated with explicit definitions: validate runs are scheduled executions over approximately two months; agent records are database rows, not revenue customers. Public Talkdesk references above reflect Talkdesk's public product pages and developer documentation as of the date of this note.