AgentStatus × Deloitte
Independent reliability evidence for every client AI deployment Deloitte advises on.
You walk into client engagements expected to have answers about AI reliability, fast. AgentStatus gives Deloitte a multi-tenant partner workspace with outside-in evidence on each client's agents in production: verdicts, regional pass rates, conformance violations, audit-ready exports. No instrumentation, no two-week setup, no access into the client's infrastructure. Point us at the public surfaces, walk in 48 hours later with data.
What we understand about Deloitte
Deloitte's AI advisory practice succeeds on what its consultants can prove, fast.
The shape of the conversation has changed. Clients deploying agents in production aren't asking can we do this, they're asking can we trust what we shipped. Deloitte engagements increasingly need to walk into the room with reliability evidence on day one, not at week six.
The bottleneck isn't analysis capacity, it's the time and access required to instrument client systems. AgentStatus removes that bottleneck. Outside-in, no integration, evidence-grade output that holds up in front of the client's CISO and risk function.
What AgentStatus is
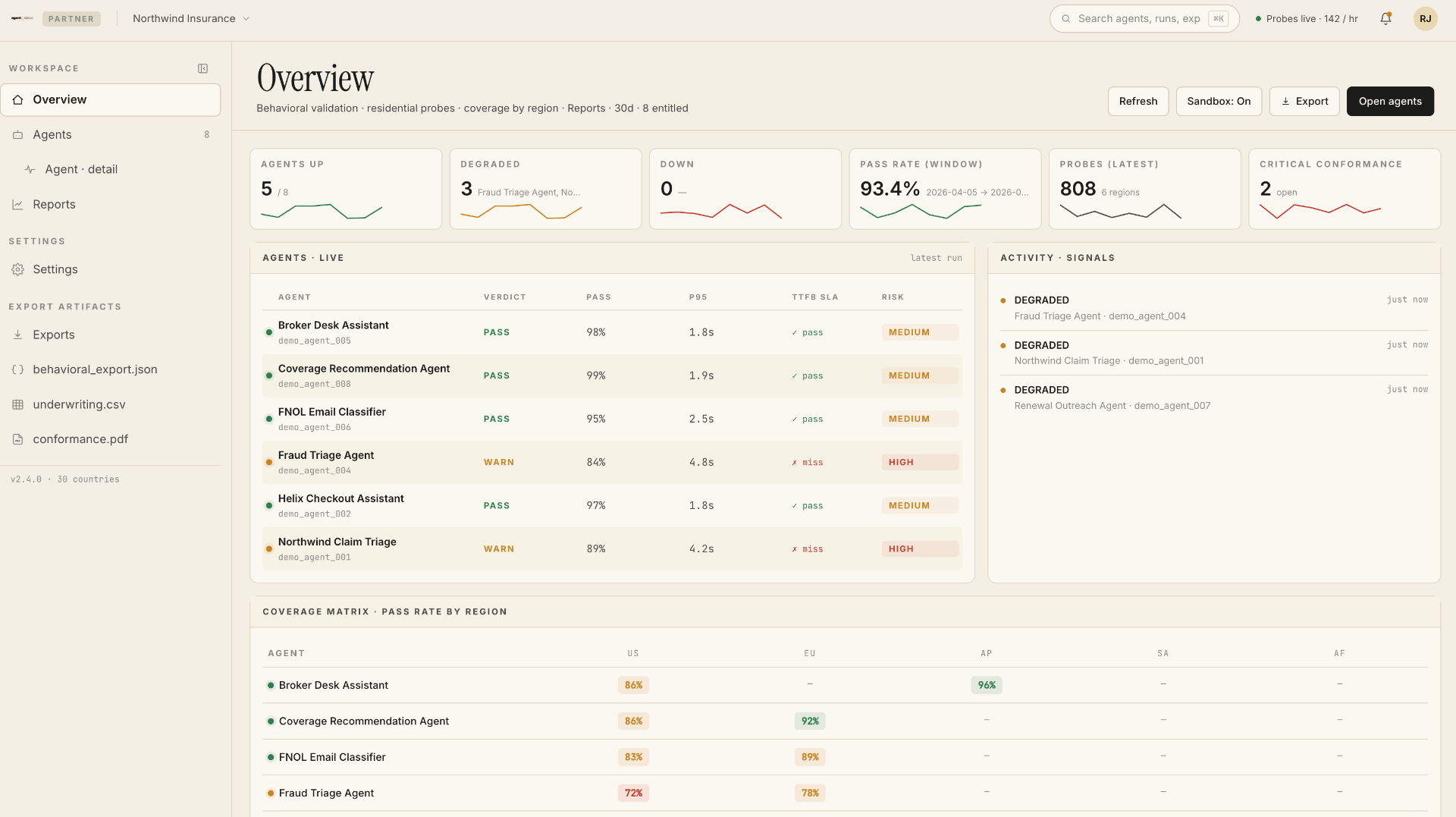
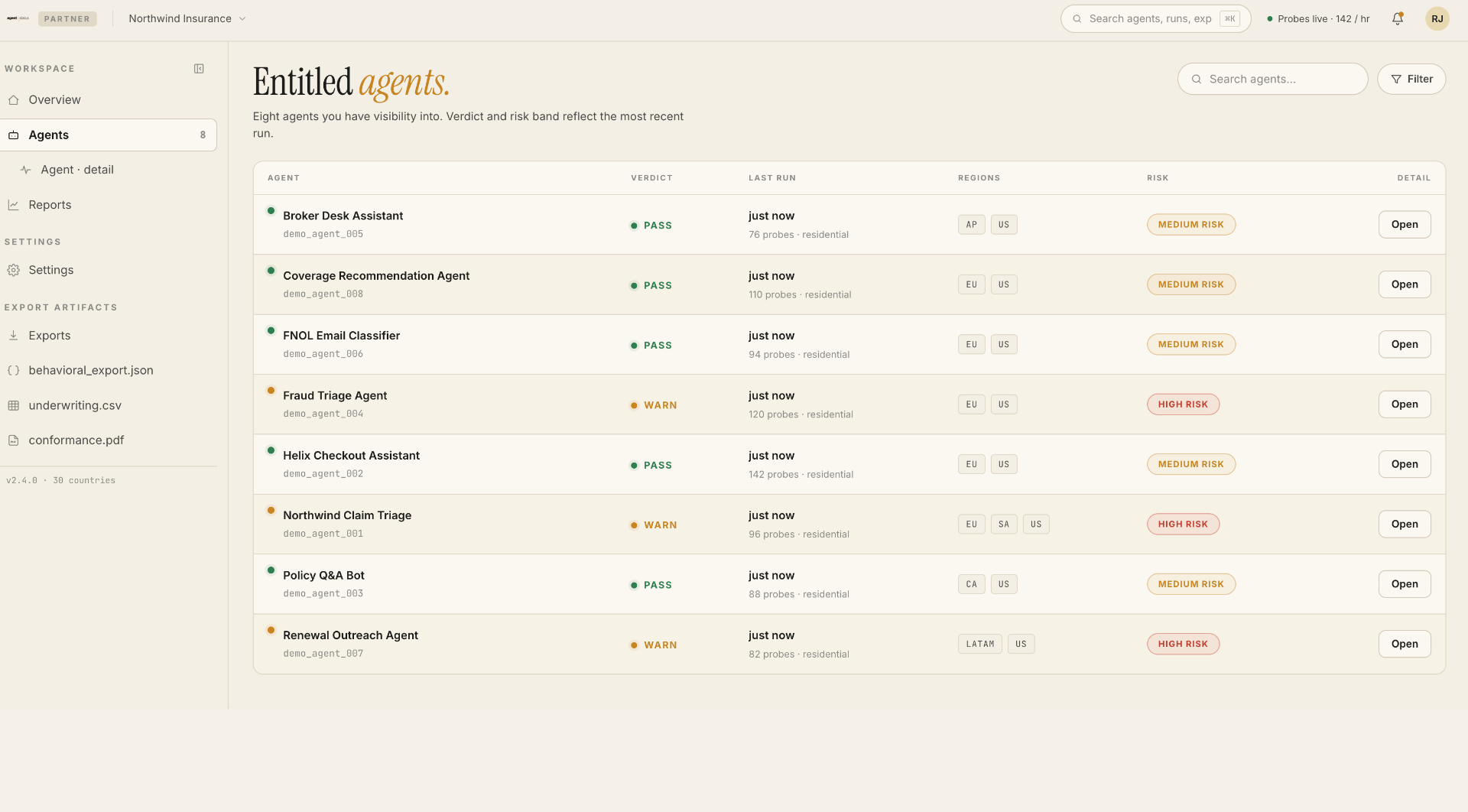
What Deloitte gets in the partner workspace.
A multi-tenant view of every client AI deployment Deloitte onboards, with the artifacts engagement teams actually need.
- Per-client workspace. One consultant login, every client's agent fleet visible, scoped cleanly per engagement.
- Live verdict mix per agent. UP, DEGRADED, DOWN, with risk bands (medium, high) on each.
- Regional coverage matrix. Pass rate per agent broken down across US, EU, APAC, SA, AF. The geography view client CISOs ask about and most monitoring tools can't produce.
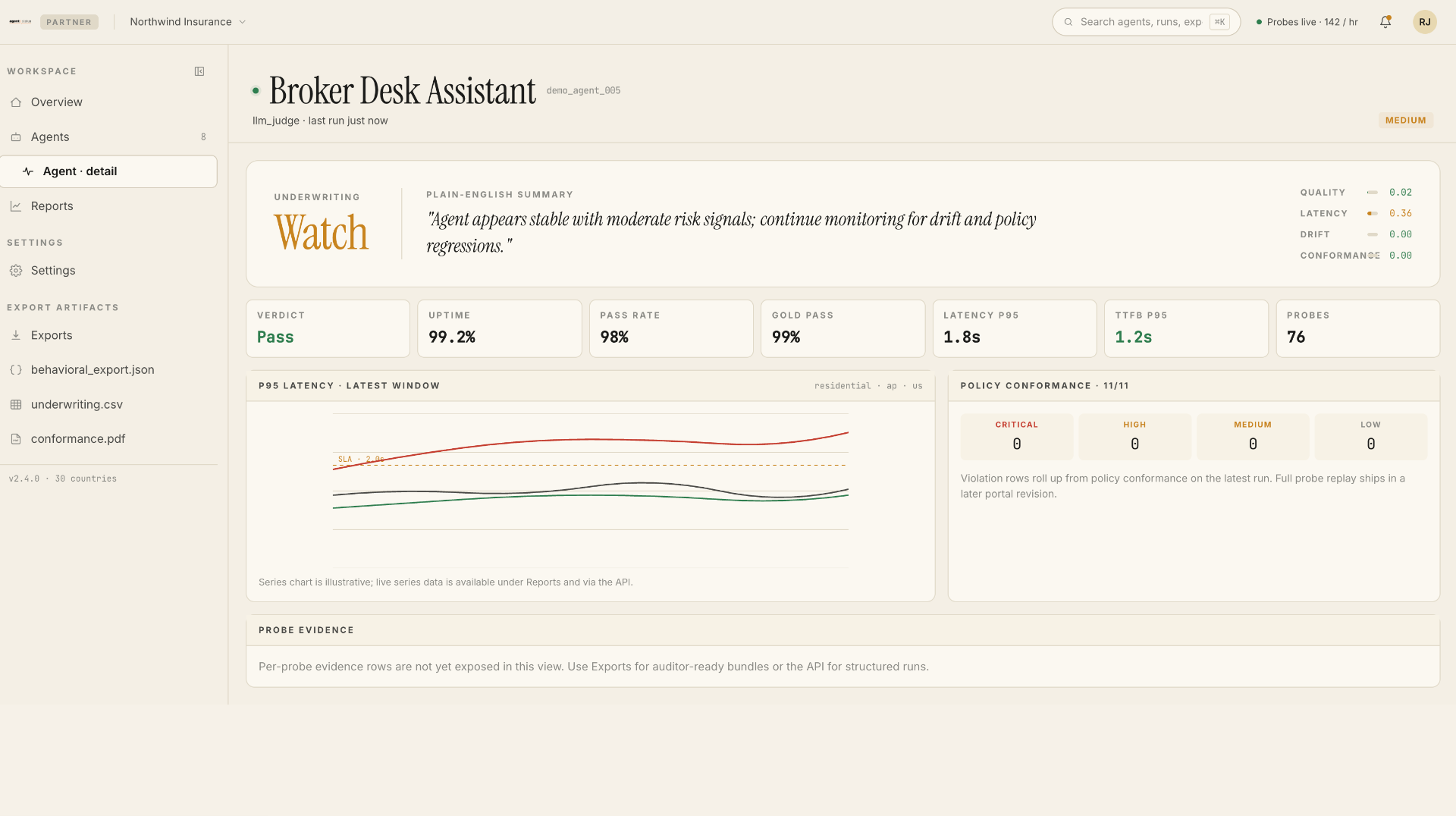
- LLM-judge scoring on Quality, Latency, Drift, Conformance. With plain-English summaries auditors and partners can quote directly.
- Policy conformance with severity tiers. Critical, high, medium, low violation counts mapped to the client's actual policy language.
- Audit-ready exports.
behavioral_export.json,underwriting.csv,conformance.pdf. Drop straight into the engagement deliverable.
Where we fit
Complement, not overlap.
Day-1 findings, not week-6 findings
Independent third-party evidence is the deliverable
Geographic and conformance angles are uniquely consultable
Coverage matrix by region and policy conformance with severity tiers are exactly the artifacts that justify premium engagement pricing. They're not what the client could have produced themselves.
The split
Two truths, one story.
Deloitte engagement, today
- • Provision client access, build eval harness
- • Findings at week 6
- • Spreadsheet evidence built by the engagement
- • Single-region or internal-trace view
- • Reliability claims in the report
Deloitte engagement, with AgentStatus
- • Point at public endpoints, evidence in 48 hours
- • Findings on day 1
- • Audit-ready exports from an independent layer
- • Pass rate across US, EU, APAC, SA, AF
- • Reliability evidence in the report
Proof of scale
Plain definitions, no inflation.
In about two months, we have executed on the order of 18 million validate runs across the network. We also maintain on the order of 6,000 agent records in our system, meaning rows and configurations we track, including evaluation and pipeline agents, not "6,000 paying customers."
We have also caught node operators trying to game the network with datacenter VMs instead of real consumer egress. Detection of adversarial behaviour is built into the product. If helpful, we can share stricter production-only definitions under NDA.
What we are not claiming
An independent layer that coexists.
We are not a replacement for Deloitte's advisory work, eval frameworks, or risk methodology. We are the independent outside-in evidence layer that makes those deliverables faster to produce and harder to dispute.
What we'd like from this conversation
Asks.
One named engagement
Pick a client where Deloitte is already advising on AI deployment, or a sandbox crew that mirrors a real one.
Public endpoints
The publicly-reachable agent surfaces we should monitor, with customer approval where appropriate.
Two-week pilot
Live dashboard, regional coverage, audit-ready export pack. Honest finding at the end: did this change what Deloitte was able to put in front of the client?
Closing
Deloitte sells reliability conversations to enterprise clients deploying AI. AgentStatus is the data underneath those conversations. We'd love to hop on a call
and walk through the partner workspace live, with one of your client engagements as the example.
Proposed pilot and partnership conversation, not an existing partnership. AgentStatus is independent outside-in production monitoring for AI agents and is not affiliated with Deloitte. Validations target publicly-reachable client surfaces with conservative rate limits and customer approval; no tenant data is collected. Findings cited or implied are anonymized representative patterns from monitoring on multi-tenant agent fleets.