
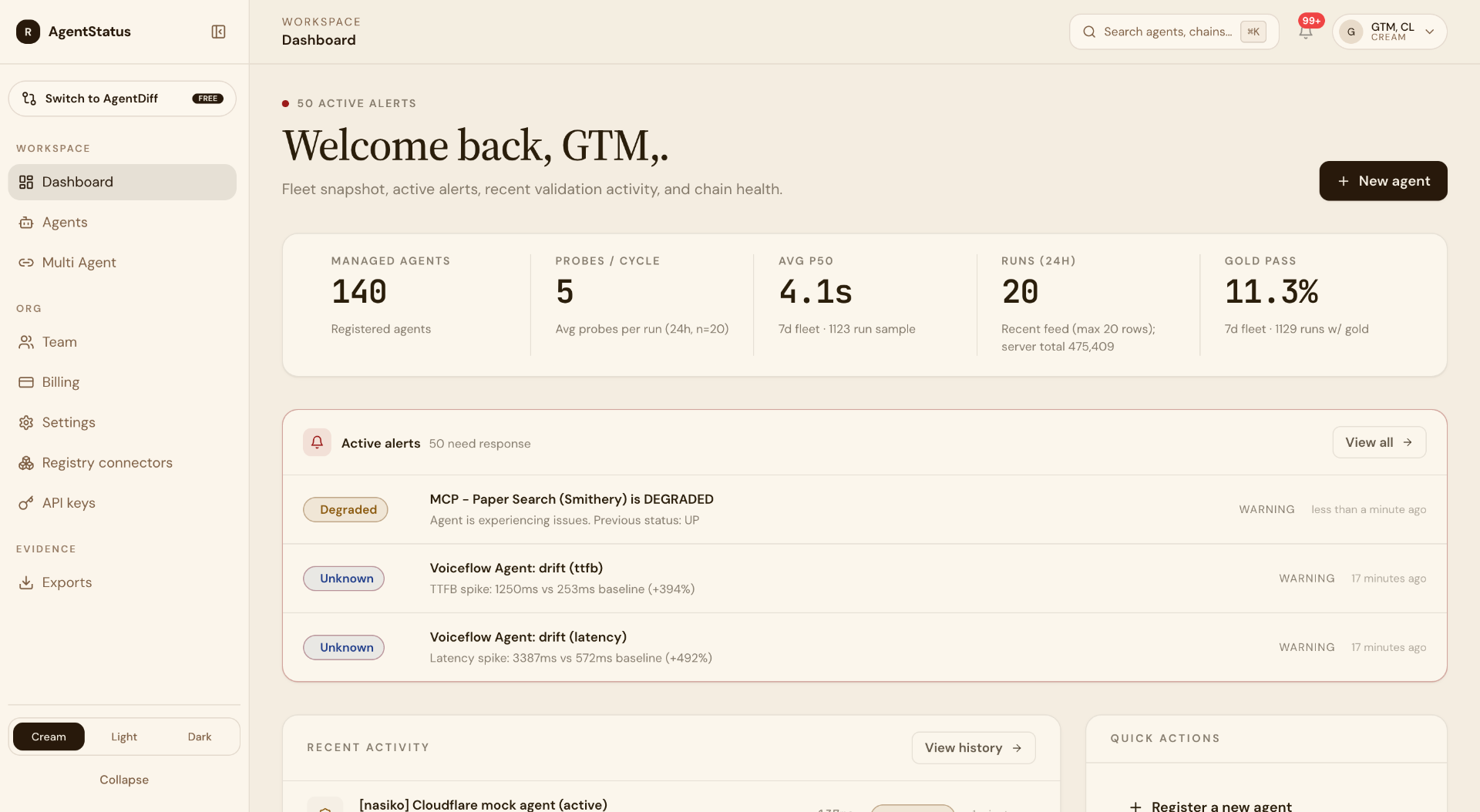
Alerts engineers can actually act on.
Every alert links to the validation that triggered it, the full request and response, the affected regions, and a recommended owner.
User-side validation isn't theory.We've been running it.
Agents continuously monitored across the global network.
USER-SIDE VALIDATIONS
Countries covered
The failure modes your current stack misses
Your first signal is a customer ticket.
By the time it lands in support, hundreds of users saw the bad answer.
The alert says 'something is wrong'. Engineering has no replay.
Without the actual response payload, the on-call has nothing to debug.
Noisy alerts get ignored.
A flaky region pages the team three times a day. Real alerts drown.
Every alert ships with the validation that caused it.
Open the alert, see the prompt, the response, the region, the verdict, and a one-click replay.
- Full request and response
- Region and exit attribution
- One-click replay
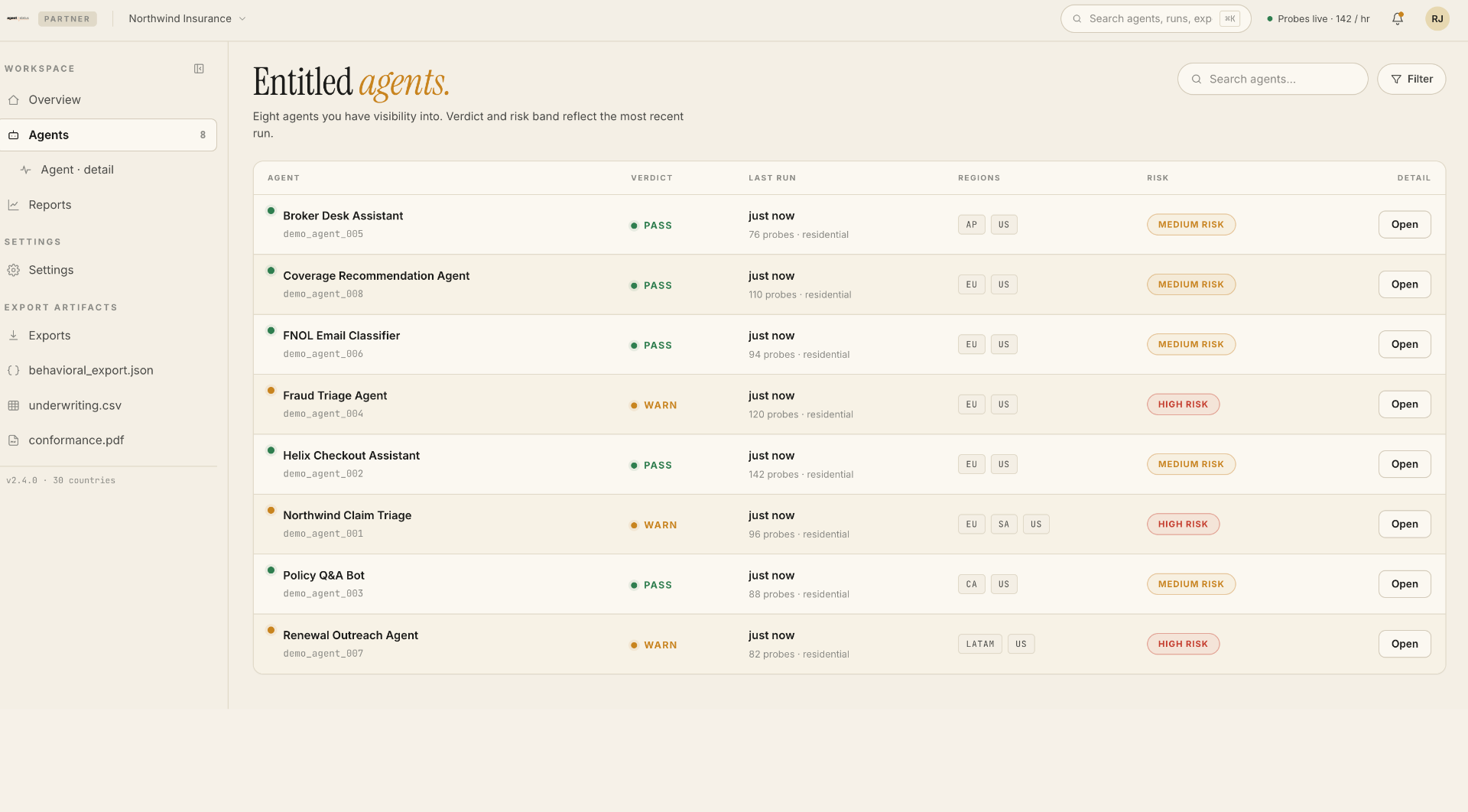
Right team, right channel, every time.
Per-agent routing rules: drift to model team, latency to SRE, conformance to compliance. PagerDuty, Slack, or webhook.
- Per-agent destinations
- Severity-aware routing
- On-call schedules
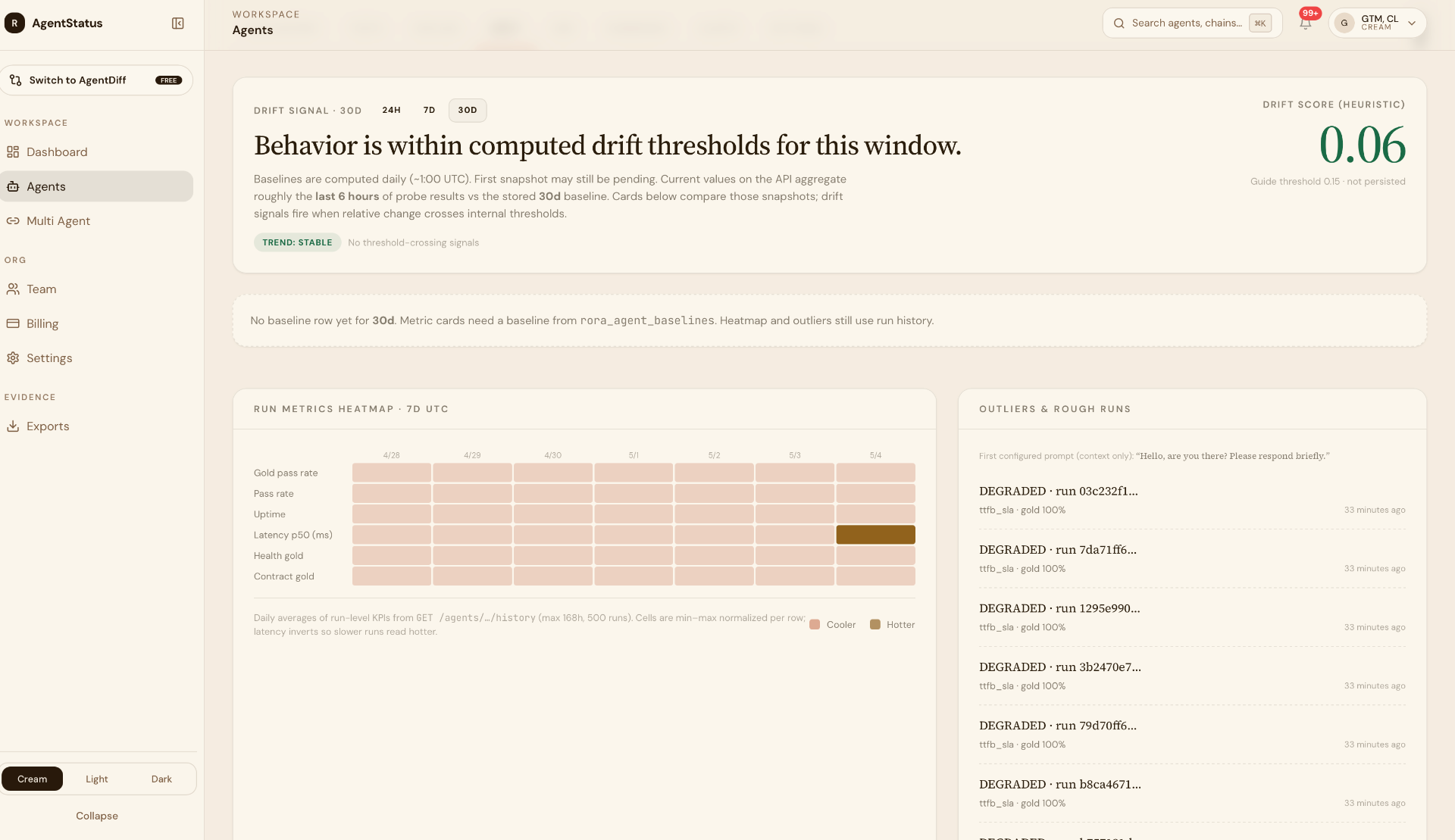
Multi-window confirmation kills flap.
Alerts confirm across windows before firing. Flaky regions can be quarantined without losing the signal.
- Multi-window confirmation
- Region quarantine
- Snooze with reason
From first validation to signed report in two weeks
Connect
Point Agent Status at the user-facing surface of your agent. No SDK, no instrumentation. Average setup is under five minutes.
Watch
Live verdicts stream in from every region you serve. Drift and latency alerts route to PagerDuty or Slack, with a signed report on every run.