

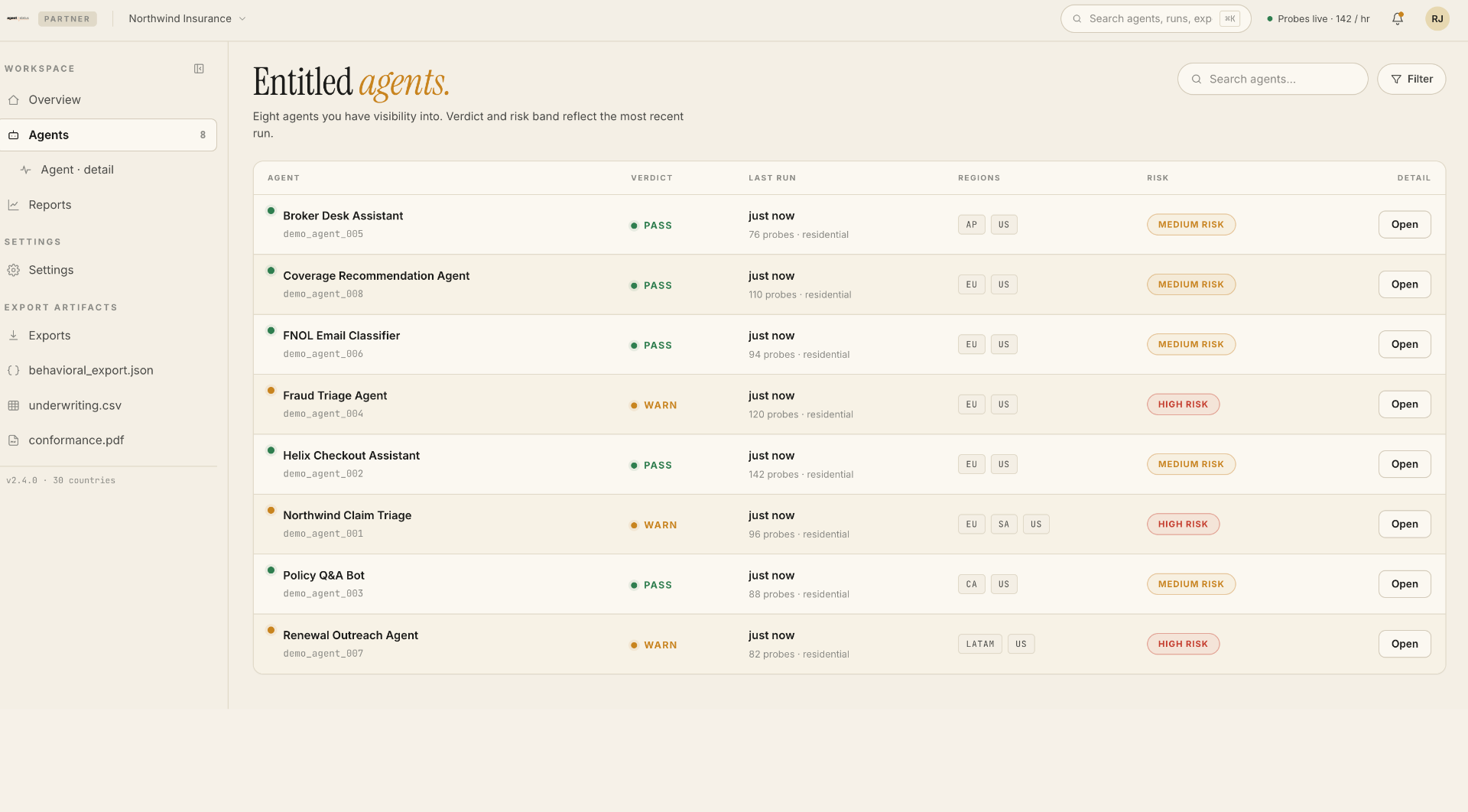
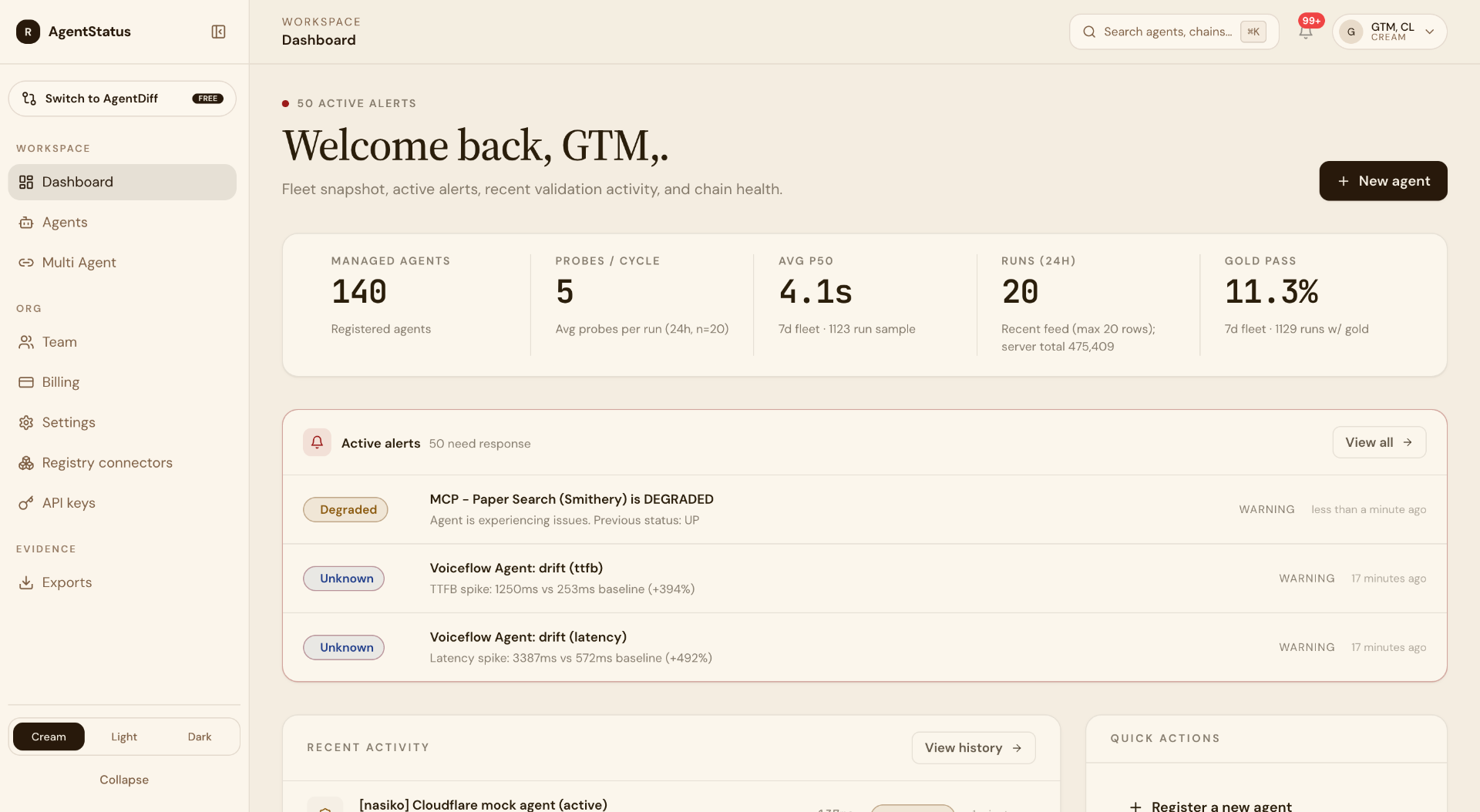

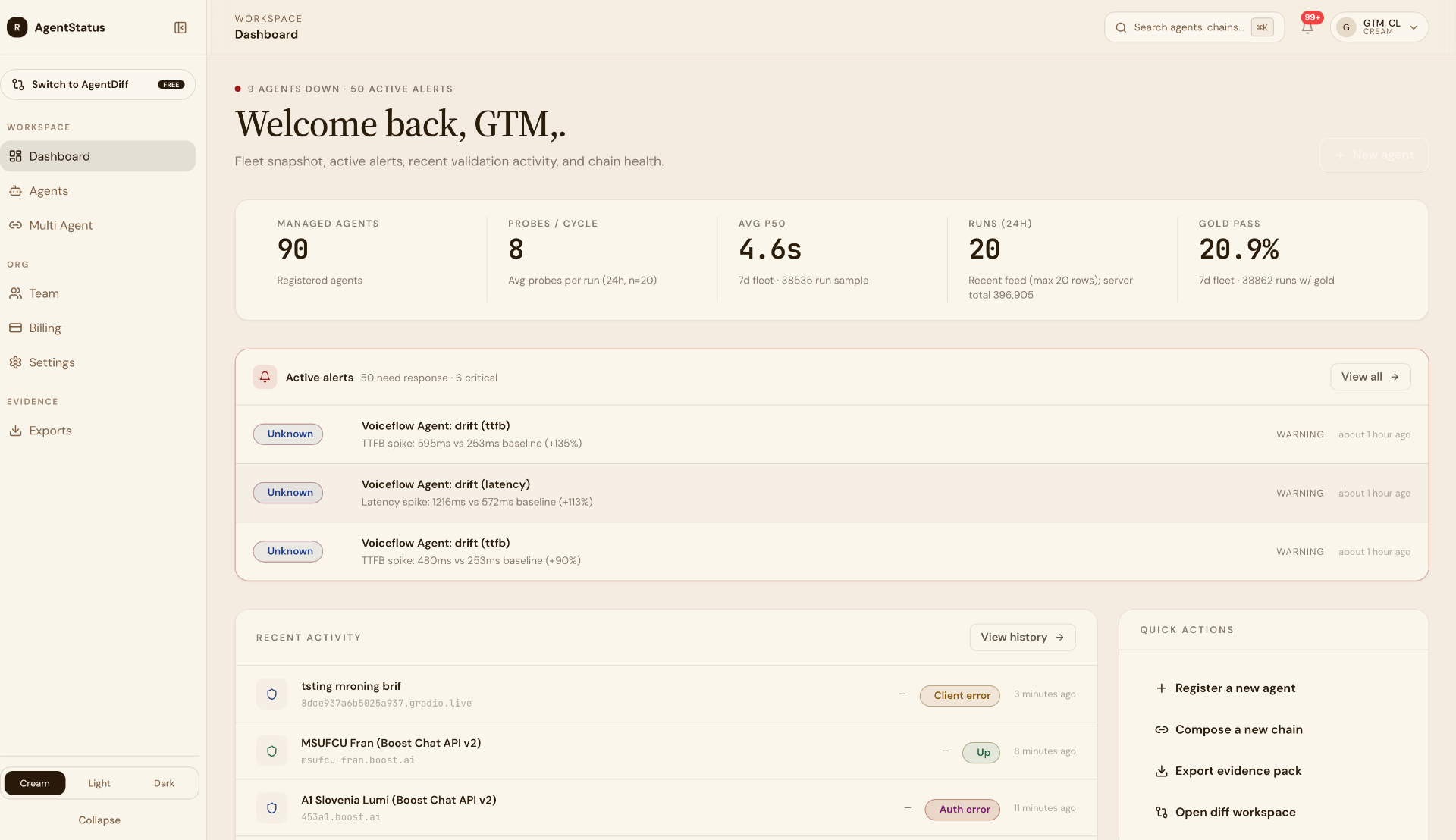

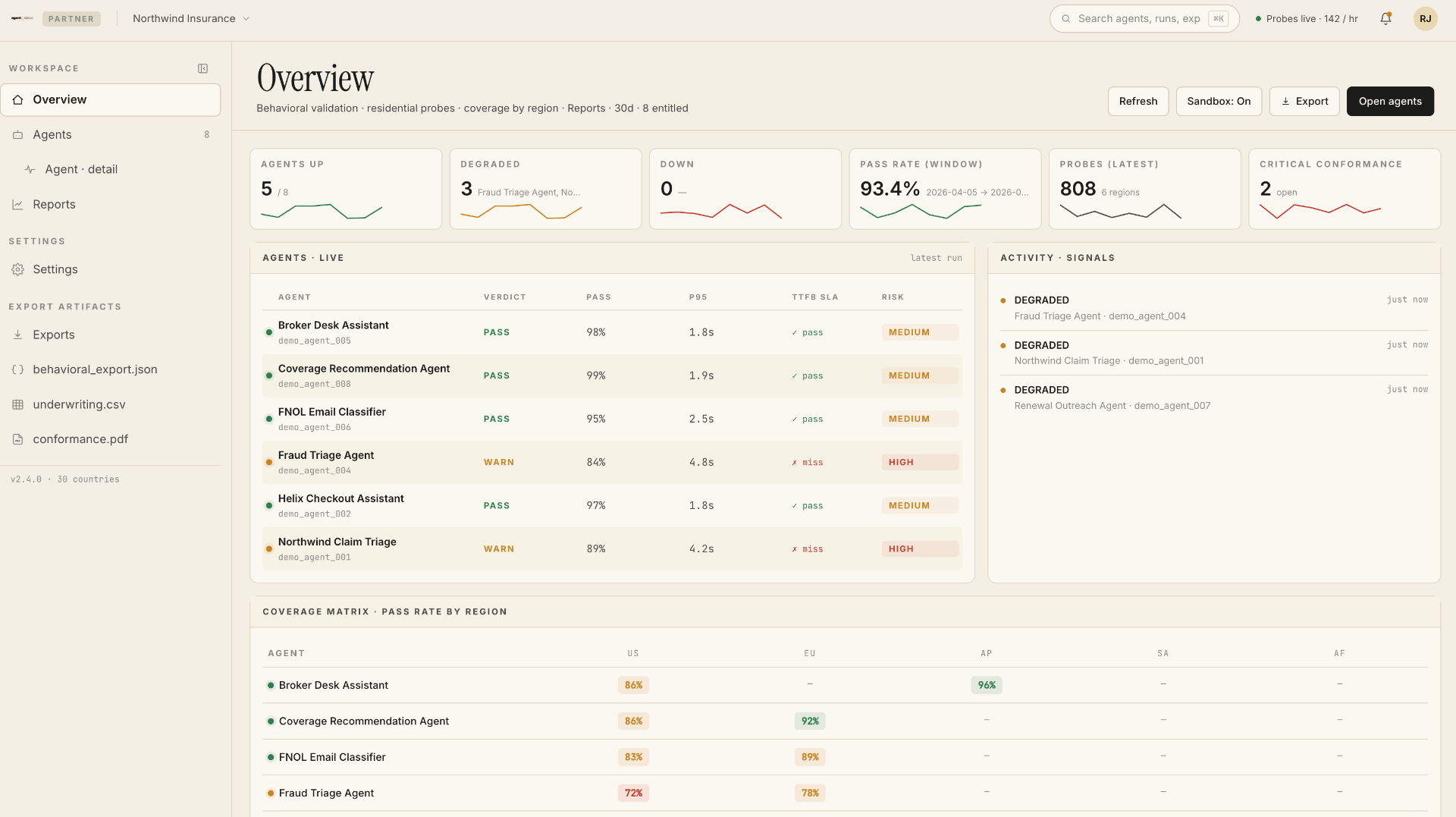
Floating-point non-associativity
(a + b) + c = 0.492371
a + (b + c) = 0.492368
— argmax flips at bit 9
GPU kernels reduce in nondeterministic order. The same logits, summed twice, do not produce the same logits.
The deterministic path is a marketing term.
 OpenAI
OpenAI Claude
Claude Anthropic
Anthropic Google
Google Azure
Azure AWS Bedrock
AWS Bedrock LangChain
LangChain Fetch.ai
Fetch.ai Forethought
Forethought ElevenLabs
ElevenLabs Retell
Retell Perplexity
Perplexity Poe
Poe Devin
Devin